Engineering
How we built a knowledge base that agents read before generating code
Token Terminal
•
Our end-to-end data pipeline runs on nearly 100 skills that produce financial and usage metrics for 100+ blockchains, 1,200+ protocols, and 3,000+ tokenized assets. We describe how we built the skills in our recent engineering blog post, Programming the onchain gigafactory.
Skills tell agents what to do. They do not explain why. When a new chain works differently from what the skill was built for, the agent is likely to copy the pattern and get the output wrong.
The reasoning behind each pattern lived in Notion docs, GitHub PRs, and Slack threads. Inspired by Andrej Karpathy's LLM knowledge base concept, we decomposed that reasoning into 50+ small, linkable files that sit in the same repository as our skills and pipeline code. Adding the decision files gave agents the reasoning alongside both.
One decision per file
Each file follows an ADR-style format. ADR stands for Architecture Decision Record, a pattern from software engineering where each design decision gets its own document. We adapted it for our data pipeline.
Each file covers one decision. It states what we chose, what we considered, and what breaks if it changes. A worked example shows the decision applied to a real model with diagrams.
Each file ends with [[double-bracket]] links to related decisions, a convention from wiki software. The Extract marginal price from pool state decision, for example, links to each pool type that implements it: [[Constant product (Uniswap V2)]], [[Concentrated liquidity (Uniswap V3)]], and so on.
One of the 50+ decision files. Each one follows the same four-section format.
How the files connect
The 50+ files are organized by pipeline stage in a directory that mirrors how data flows through the system. Each stage groups its decisions into a folder, with a topic-level file as the entry point. An agent working on a price model starts at Pool pricing, reads the decisions that apply, and follows links into the specific pool type it needs.
A subset of the directory. The highlighted file is the decision file shown earlier.
The files are versioned alongside the pipeline code they describe. An engineer updating a design decision updates the file in the same pull request as the code change.
The links between files form a navigable graph. An agent does not read all 50+ files. It follows links from one decision to the next, pulling only the reasoning it needs for the current task. Tools like Obsidian render these links visually. Each color is a pipeline stage. The clusters show which decisions are tightly related and where one stage's decisions depend on another's.
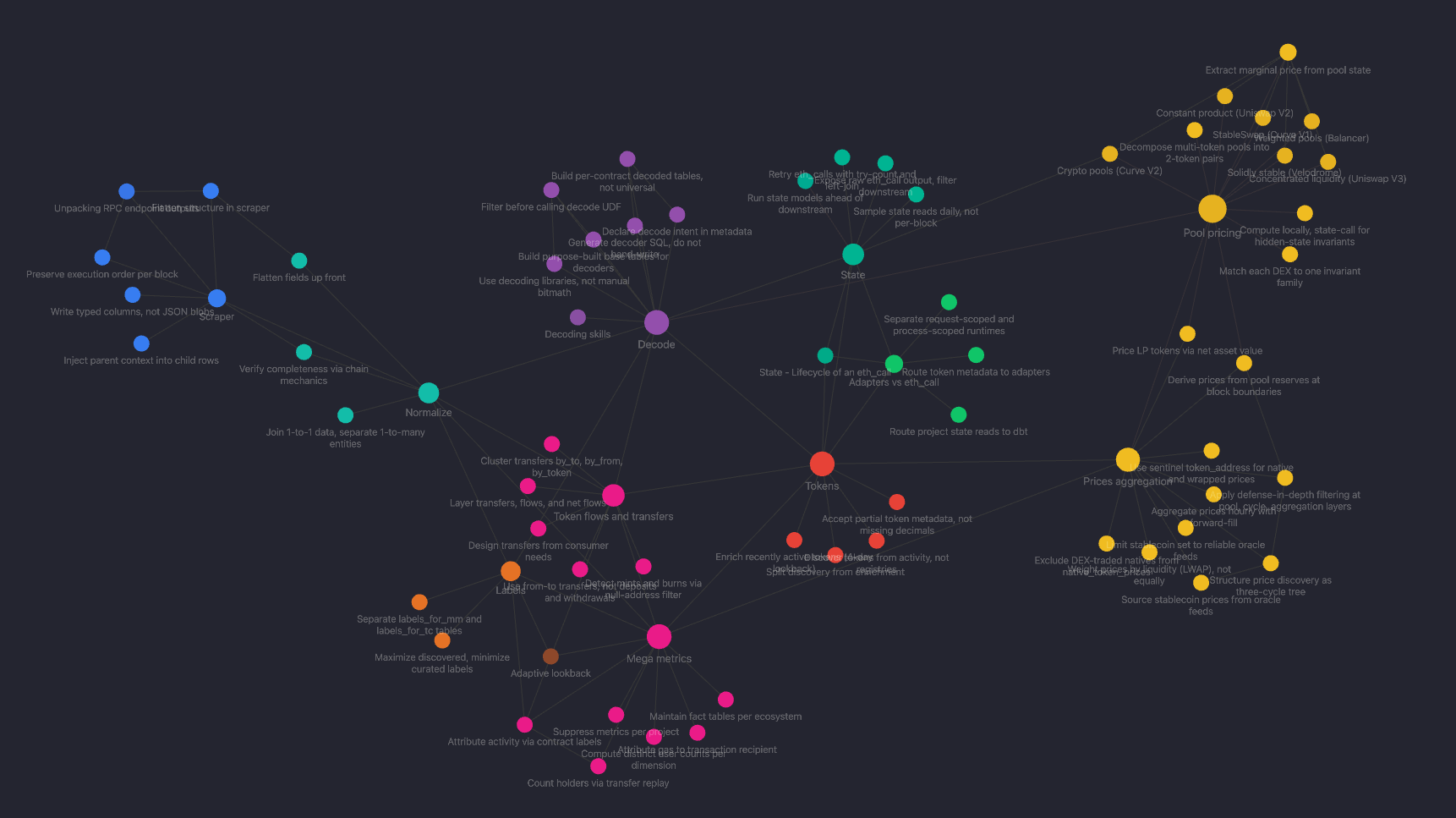
The knowledge graph rendered in Obsidian. Each node is a decision file. Each color is a pipeline stage.
What this enables
Agents produce more accurate pull requests on the first pass. An agent reads ~300 tokens of directly relevant reasoning rather than a 2,000-word topic doc. When a new chain works differently, the agent finds the reasoning instead of copying the pattern blind.
Better first drafts mean faster reviews. When a reviewer catches something wrong, they point to the decision file instead of re-explaining the reasoning from scratch. The review becomes "see this file" instead of a paragraph of context in a comment thread.
Faster reviews feed back into the knowledge base. A reviewer who updates a decision file after catching an issue makes that fix permanent. The next agent reading that file gets it right without the same review. Each fix makes the next run better, and the runs compound.
We believe this is the fastest path to agents that can run our end-to-end data pipeline autonomously.The authors of this content, or members, affiliates, or stakeholders of Token Terminal may be participating or are invested in protocols or tokens mentioned herein. The foregoing statement acts as a disclosure of potential conflicts of interest and is not a recommendation to purchase or invest in any token or participate in any protocol. Token Terminal does not recommend any particular course of action in relation to any token or protocol. The content herein is meant purely for educational and informational purposes only, and should not be relied upon as financial, investment, legal, tax or any other professional or other advice. None of the content and information herein is presented to induce or to attempt to induce any reader or other person to buy, sell or hold any token or participate in any protocol or enter into, or offer to enter into, any agreement for or with a view to buying or selling any token or participating in any protocol. Statements made herein (including statements of opinion, if any) are wholly generic and not tailored to take into account the personal needs and unique circumstances of any reader or any other person. Readers are strongly urged to exercise caution and have regard to their own personal needs and circumstances before making any decision to buy or sell any token or participate in any protocol. Observations and views expressed herein may be changed by Token Terminal at any time without notice. Token Terminal accepts no liability whatsoever for any losses or liabilities arising from the use of or reliance on any of this content.
Stay in the loop
Join our mailing list to get the latest insights!