Engineering
How a reasoning layer makes 2 petabytes of onchain data accessible through one question
Token Terminal
•
When an AI agent asks for "Ethereum fees", it could mean at least three different things. Ethereum as a blockchain network that collects gas fees. Ethereum as an ecosystem where thousands of applications earn their own fees. Or a specific metric that varies depending on whether you include or exclude blob fees, priority fees, or burned ETH.
Multiply this ambiguity across 100+ blockchains, 300+ projects, and 200+ metric definitions, and you get a problem that no amount of prompt engineering can solve.
This ambiguity isn't a model weakness. It's an interface mismatch: natural language is fuzzy, but data systems are strict. The challenge is not prompting better – it's building a system that can reliably resolve intent into precise, validated data definitions.
The foundation that makes this possible
Token Terminal operates a full-stack data infrastructure that spans more than 2 petabytes of raw blockchain data across 100+ chains, managed through over 20,000 SQL transformation models. Building this took years.
Each chain family – EVM, Solana, Cosmos, Move, Polkadot – required its own ingestion logic, its own decoding framework, and its own set of standardization rules. Scaling it to process roughly 200 terabytes of new data daily, while keeping every metric accurate and auditable, is an ongoing effort that touches every part of the company.
But this investment is exactly what makes Token Terminal's MCP server different from a generic API wrapper. Because we own the entire pipeline – from raw block data through decoding, interpretation, and standardization – the MCP server can resolve questions using the same canonical definitions, entity mappings, and transformation logic that power our data warehouse.
Rather than inferring meaning from surface-level descriptions, it operates against an indexed registry of projects, products, assets, chains, metrics, availability constraints, and methodology definitions. That depth of context is only possible when you control the full transformation pipeline end to end.
The challenge was making all of this accessible through a single question.
Why enumeration fails at scale
Our first AI integration followed the obvious approach: give the model a complete list of projects, chains, and metrics so it could select the right ones. It worked – technically.
But a single call to list available projects consumed 17,400 tokens of context before the model had even asked a question. Six of our eight tools existed just to enumerate entities.
As our coverage grew past 250 projects and 100 chains, this approach broke down. Token cost per conversation was high, latency was noticeable, and models frequently hallucinated entity IDs because the full list was too long to process reliably.
The more data we added to the platform, the harder it became for AI agents to use it. We were solving the wrong problem.
So we reframed it: if full enumeration doesn't scale, what does?
Three approaches we considered
Vector search. Embed entity descriptions and retrieve by similarity. This handles fuzzy matching well but fails at our core challenge: the same name maps to different entity types depending on context. "USDC" is simultaneously a product (under Circle), and an asset (the token). Similarity scores don't capture this kind of taxonomy.
Structured API with type-ahead search. Fast and predictable, but it pushes the interpretation work onto the client model, which doesn't understand our data model well enough to ask the right follow-up questions.
A sandboxed agent with a local knowledge base. A small, fast language model with access to our full entity taxonomy through a local database, no internet access, and a strict tool budget.
This is what we built.
How the brain works
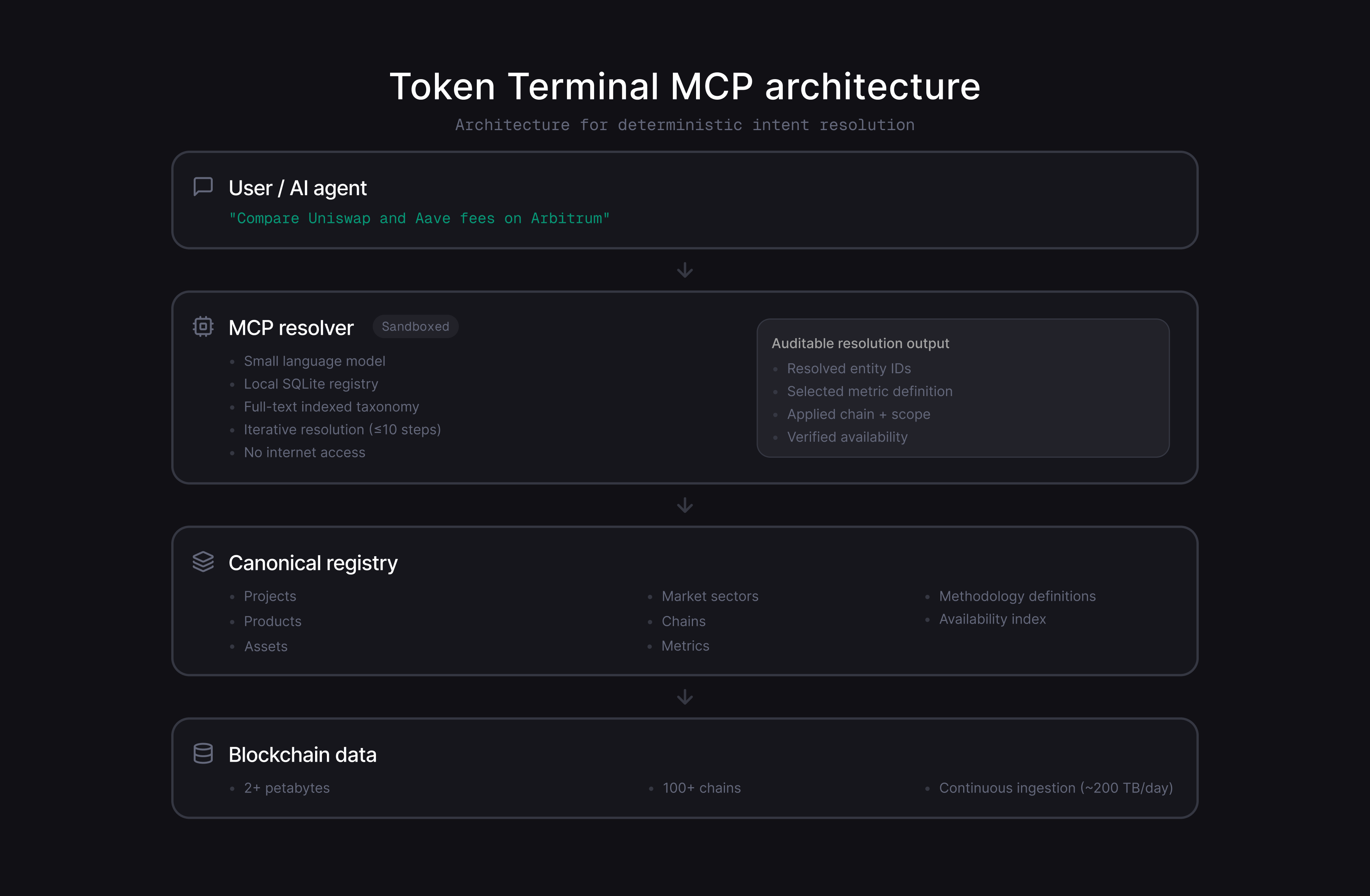
The system runs inside a sandboxed environment with internet access turned off. Inside, a small language model has one tool available: a SQLite database containing our complete entity taxonomy – projects, products, assets, chains, market sectors, metrics, per-entity metric availability, and methodology descriptions. Full-text indexes make cross-entity lookups fast.
When a user asks "compare Uniswap and Aave fees on Arbitrum," the brain resolves this to precise IDs: Uniswap and Aave as project entities, Arbitrum as a chain filter, and fees as the target metric. It also checks whether both projects actually report fee data on Arbitrum before returning the result.
The response includes the resolved entity identifiers, the selected canonical metric definition, the applied chain and scope filters, and verification that the metric is available for each entity. This makes the output not just useful, but auditable. At scale, an AI interface that cannot explain which definition it used, which scope it applied, and whether the data actually exists becomes a liability. Auditability is not a feature layer on top – it is a structural requirement for correctness.
The sandboxed model can take up to ten iterative steps, querying the database to resolve ambiguity. Externally, the interface stays simple: one natural language question in, one structured response out.
One tool call, 1–7 cents, ~200 tokens of structured output.
What changed
This replaced eight tools with one. But the bigger shift was in the interaction model.
Previously, any AI agent that wanted to use our data needed to understand our internal taxonomy – the difference between a data_id and a chain_id, that products require parent project references, that some entities exist as both assets and products. Now it sends a plain question and gets back exactly the identifiers it needs, with availability already verified.
The system acts as a deterministic resolver between natural language and canonical data definitions, rather than a heuristic best-match layer.
The layer that matters most
There's a pattern here that goes beyond Token Terminal. Building a large, accurate database is necessary but not sufficient. Making it available through an API is not enough either.
The real leverage sits between the two – a layer that interprets what a user is actually asking, navigates a complex taxonomy on their behalf, and finds the most direct path to the right answer.
What makes this layer powerful isn't the model inside it. It's the depth of context it can draw on. Because Token Terminal owns every stage of the data pipeline, the system can draw directly from canonical methodology, standardized transformations, and entity mappings.
Without this layer, more data just means more ways to get the wrong answer. With it, the entire warehouse becomes accessible through a single question.
That's the difference between a data warehouse and an intelligence layer – and it's what makes Token Terminal's MCP server work at scale.
The authors of this content, or members, affiliates, or stakeholders of Token Terminal may be participating or are invested in protocols or tokens mentioned herein. The foregoing statement acts as a disclosure of potential conflicts of interest and is not a recommendation to purchase or invest in any token or participate in any protocol. Token Terminal does not recommend any particular course of action in relation to any token or protocol. The content herein is meant purely for educational and informational purposes only, and should not be relied upon as financial, investment, legal, tax or any other professional or other advice. None of the content and information herein is presented to induce or to attempt to induce any reader or other person to buy, sell or hold any token or participate in any protocol or enter into, or offer to enter into, any agreement for or with a view to buying or selling any token or participating in any protocol. Statements made herein (including statements of opinion, if any) are wholly generic and not tailored to take into account the personal needs and unique circumstances of any reader or any other person. Readers are strongly urged to exercise caution and have regard to their own personal needs and circumstances before making any decision to buy or sell any token or participate in any protocol. Observations and views expressed herein may be changed by Token Terminal at any time without notice. Token Terminal accepts no liability whatsoever for any losses or liabilities arising from the use of or reliance on any of this content.
Stay in the loop
Join our mailing list to get the latest insights!